Code Slop Isn't a Model Problem, It’s a Harness Problem
Right when you're entering the flow state of your programming session, your agent starts drifting. The code still compiles. It just isn't what you asked for anymore.
I watched this happen dozens of times at Wyndly, shipping production features with an LLM coding agent in long single-agent sessions. The pattern was always the same: sharp start, clean decisions, then a slow decay as the context window filled with abandoned approaches, stale error messages, and files the agent read once and never referenced again. Every token of noise competing with the tokens that matter.
The model didn't get dumber. The relevant context got buried under irrelevant context. And that's when I realized: the model wasn't the problem. The model was fine. What was missing was everything around the model — the process, the feedback, the memory, the isolation. I was blaming the engine for a chassis problem.
I identified five specific problems that cause an agent to meander from brilliant to foolish:
Context Rot
The Specification Gap
The Feedback Vacuum
Amnesia
Isolation Failure
Each one of these problems causes the agent to waste time and tokens on unnecessary work, retreading their steps, and generally being dumb.
But the five problems I'll describe here aren't specific to swarms. You'll hit every one of them with a single agent in a single session.
I've since built Oro, an agent swarm orchestrator that coordinates multiple agent workers to write, test, review, and merge code. But the five problems I'll describe here aren't specific to swarms. You'll hit every one of them with a single agent in a single session.
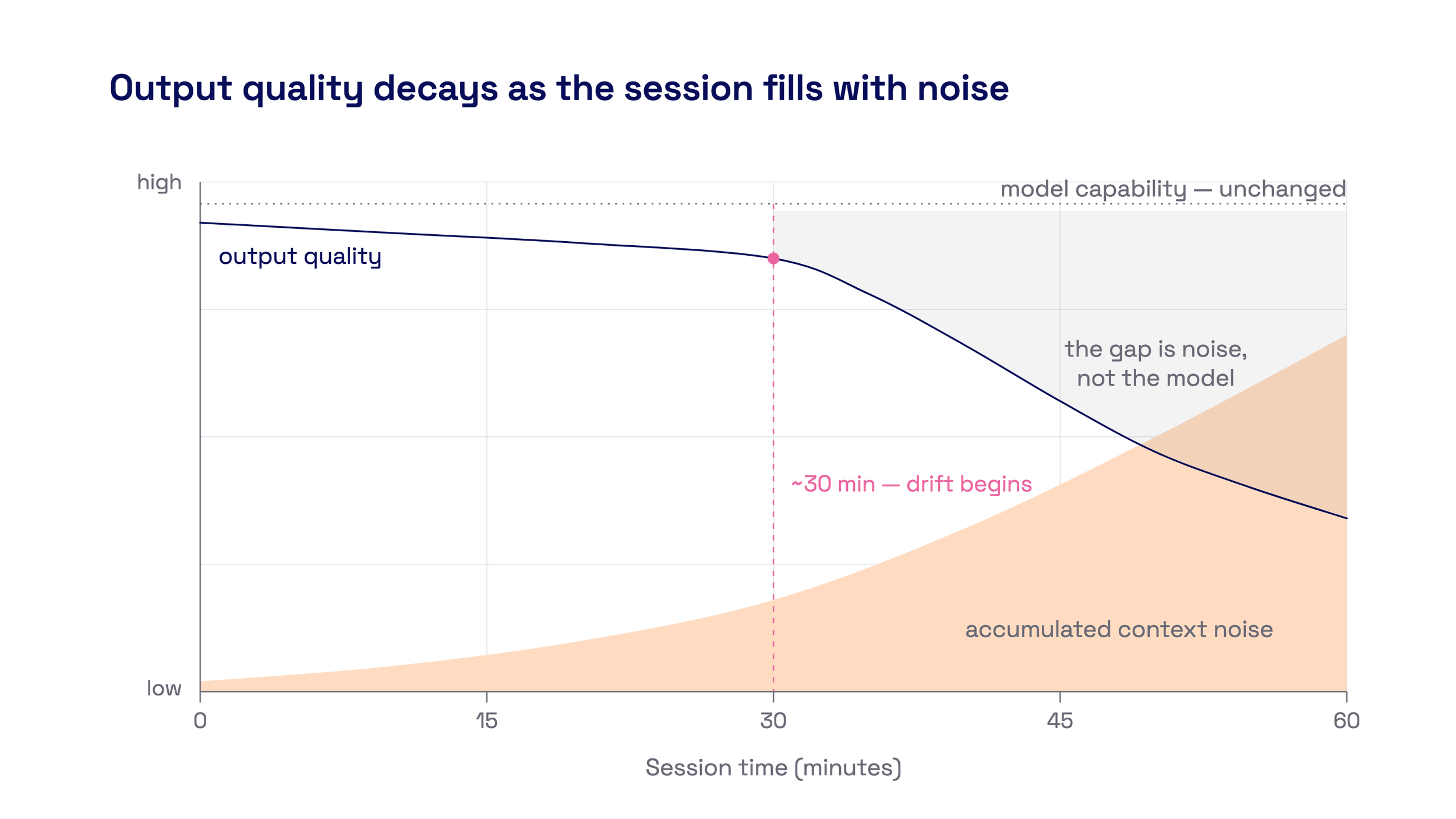
Agent output quality vs. session time. The signal-to-noise ratio degrades continuously.
1. Context Rot
Problem: The longer an agent works, the worse its output gets.
After 40 minutes, the context is packed with the full text of files read once, resolved discussions nobody will reference again, three abandoned approaches to a problem that's already solved. The model is still attending to all of it. The signal-to-noise ratio degrades continuously, and the output degrades with it.
Solution: Counterintuitively, give the agent less.
Each worker in Oro gets a single task — one atomic unit of work with clear acceptance criteria — in a clean git worktree. No history from prior tasks. No accumulated conversation. When a worker exhausts its context window, it executes a handoff and a fresh worker continues in the same worktree. The context resets. The work doesn't.
A worker that sees 200 lines of relevant code outperforms one drowning in 20,000 lines of everything. It works faster with less dead ends.
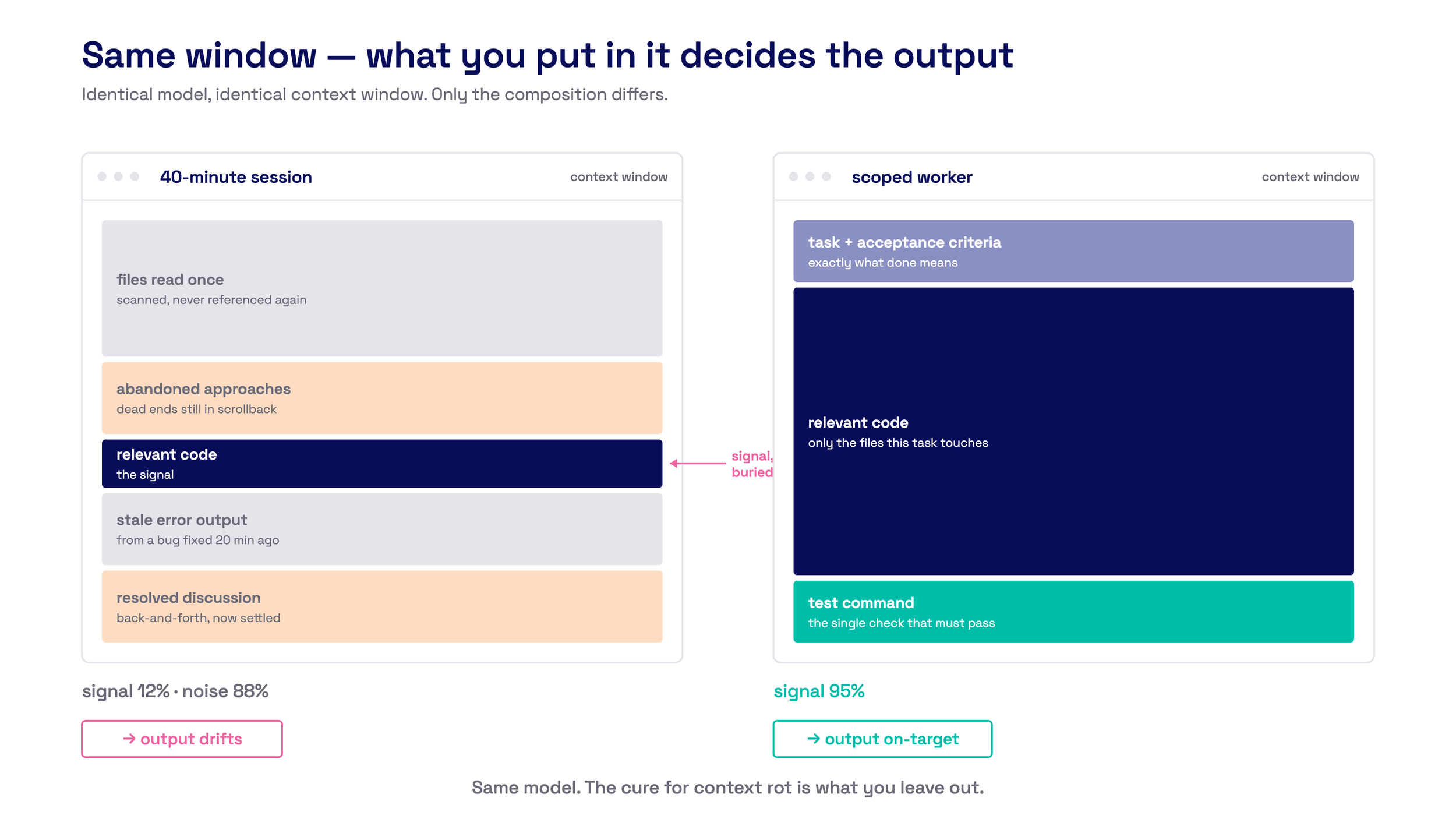
Same model, same window - only the composition differs. The fix for context rot is what you leave out.
2. The Specification Gap
Problem: Ask an agent to "add authentication" and you'll get something that compiles. You probably won't get what you meant.
Most slop originates here — not because the model can't code, but because it was given a vague target and hit it precisely. Vague spec in, vague code out. The model did exactly what you asked. The problem is what you asked.
Solution: Not more detailed prompts — a process that forces specificity before code exists.
Before any Oro worker writes a line of code, the spec runs through a gauntlet.
- Brainstorm 2-3 approaches with explicit trade-offs.
- Premortem every decision — what kills this in three months?
- Write a design doc. Then hand the doc to a separate agent, one that never saw the design conversation, whose only job is adversarial: Construct a scenario where every task passes individually but the feature still doesn't work.
- That reviewer traces actual call chains in the source code. It builds a matrix mapping every acceptance criterion to a specific task and test. It red-teams the decomposition. If it finds a gap — an unwired component, a missing integration test, a format mismatch between producer and consumer — the spec goes back for revision.
A token spent on specification saves ten tokens spent on rework. Every ambiguity resolved upstream is a hallucination that never happens downstream.
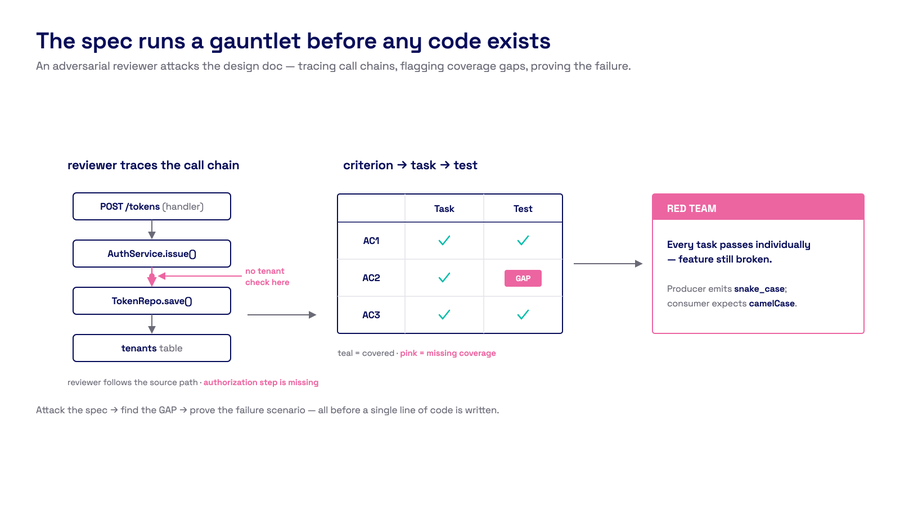
The adversarial reviewer attacks the spec before any code exists. Red lines trace call chains. GAP markers flag missing coverage.
3. The Feedback Vacuum
Problem: A human developer gets feedback constantly — the compiler, the test suite, the linter, the code reviewer, the tech lead who asks "why did you do it this way?"
An agent coding alone gets none of this. It writes code into silence.
The model can produce correct code. But without feedback loops, it has no way to distinguish correct from almost-correct. It can't know that the function it wrote matches the interface but handles errors differently than every other function in the codebase. It can't know that the test passes but doesn't actually test the thing that matters.
Solution: Make something push back — automated feedback the agent can't skip (also known as backpressure).
Oro wraps every unit of work in three independent gates.
- A 19-check quality gate — tests with race detection, linters, formatters, vulnerability scanners. Mechanical, deterministic, with no judgment required.
- a code review by a separate agent runtime instance that reads the diff against the acceptance criteria and the original spec, returning APPROVED or REJECTED with specific feedback.
- Human PR review
The worker cannot merge to prod without passing all three. Not "should pass" — cannot. Guards you can't skip are more valuable than best practices you should follow.
There's a secondary benefit here, too. Deterministic workflows let the agent keep instruction prompts focused on the problem at hand.
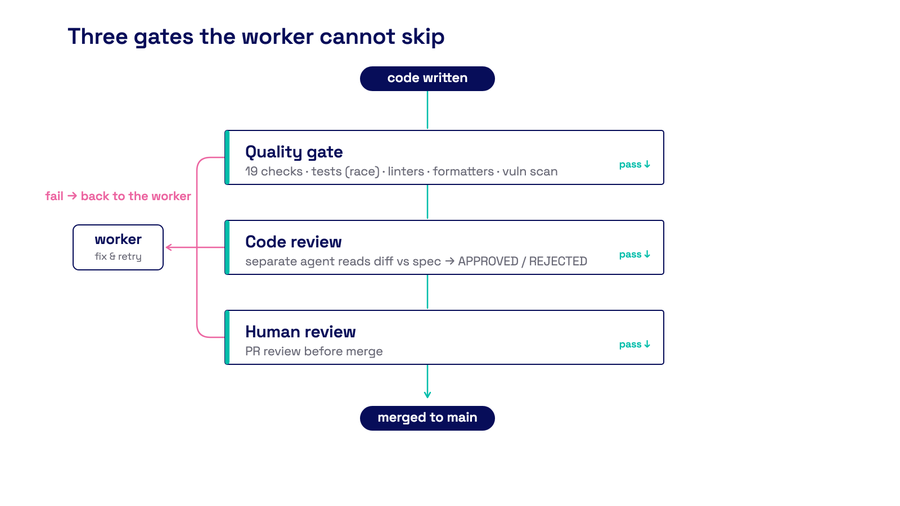
Three independent gates between code and production. The worker cannot skip any of them.
4. Amnesia
Problem: Every new coding session starts from zero. The agent doesn't remember that you prefer early returns, that the test database needs a specific seed, or that the last three attempts at this exact approach all failed for the same reason.
Humans build institutional knowledge over months. Agents lose theirs every time the context window resets.
Solution: Oro maintains a persistent memory store that workers read from and write to. Workers emit learnings during execution — patterns, decisions, gotchas. Before assigning a task, the dispatcher queries the top relevant memories and injects them into the worker's prompt, annotated with age so workers verify stale claims against current code.
Oro agents even dream. Every ten completed tasks, a consolidation agent reads the entire memory table and synthesizes across sessions — merging duplicates, deleting contradictions, surfacing patterns that no individual worker could see. A gotcha encountered in week one prevents the same mistake in week eight, without a human curating anything. The swarm accumulates judgment the way a team does, except it never forgets and it never leaves.
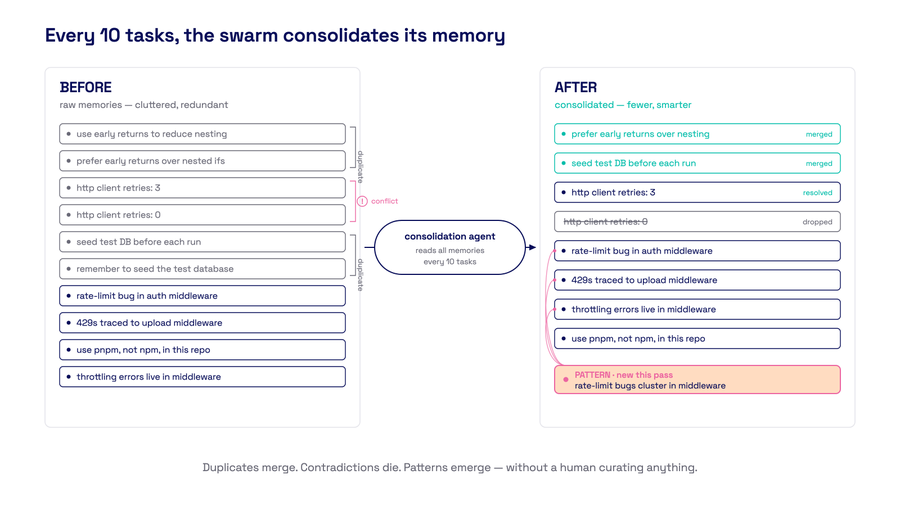
Every 10 tasks, a consolidation agent synthesizes across sessions. Duplicates merge. Contradictions die. Patterns emerge.
5. Isolation Failure
Problem: The moment you want two agents working concurrently, everything breaks. They edit the same files. They make conflicting architectural decisions. They produce interfaces that compile independently but don't agree with each other.
Two agents produce occasional conflicts. Four agents produce constant ones. The naive solution — run them sequentially — throws away the only reason you have multiple agents.
Solution: Each Oro worker operates in its own git worktree on its own branch. They cannot see each other's uncommitted changes. When a worker finishes, a coordinator serializes the merge: rebase, verify the quality gate passes on the rebased code, then fast-forward into the main branch. If a rebase conflicts, a separate agent resolves it. Linear history, every commit tested, no silent collisions.
Isolation makes concurrency possible. Without it, you're just running multiple agents in the same room with the lights off.
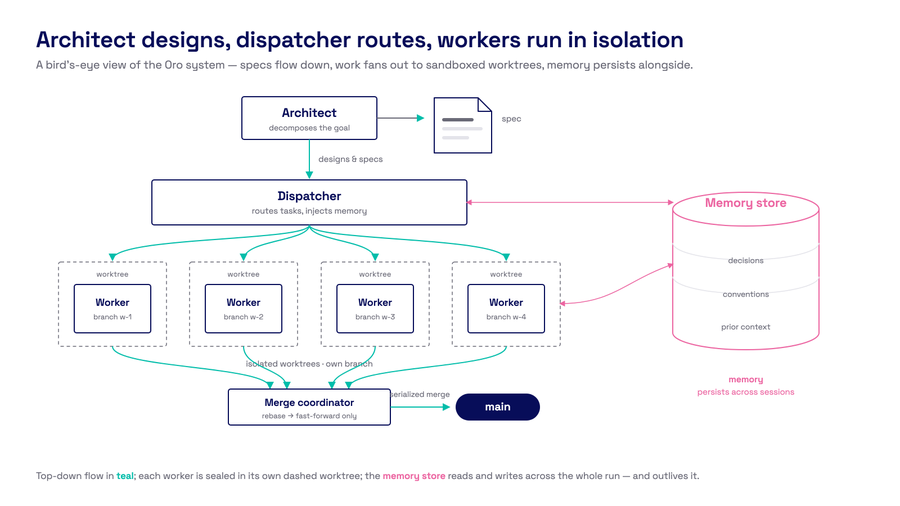
The full system. Architect designs, dispatcher coordinates, workers execute in isolation, memory persists across sessions.
The Harness Is Universal
These five problems — context rot, specification gaps, feedback vacuums, amnesia, isolation failure — aren't exotic. They're what happens every time you hand an LLM a coding task without structure around it. You can solve them with Oro, or with your own tooling, or with discipline and a checklist. But you can't ignore them and expect clean output.
Scope the context. Specify before you generate. Add mechanical feedback that can't be skipped. Persist what you learn. Isolate concurrent work.
A better model in a bad harness still produces slop. A good model in a good harness compounds. The model was never the bottleneck.
Oro is an open-source autonomous agent swarm orchestrator. It coordinates agent workers to execute software engineering tasks with TDD, quality gates, code review, and cross-session memory baked into every cycle.