
Code Slop Isn't a Model Problem, It’s a Harness Problem
Model don't get dumber. Relevant context only gets buried under irrelevant context. What’s missing is everything around the model — the process, the feedback, the memory, the isolation.
Right when you're entering the flow state of your programming session, your agent starts drifting. The code still compiles. It just isn't what you asked for anymore.
I watched this happen dozens of times at Wyndly, shipping production features with an LLM coding agent in long single-agent sessions. The pattern was always the same: sharp start, clean decisions, then a slow decay as the context window filled with abandoned approaches, stale error messages, and files the agent read once and never referenced again. Every token of noise competing with the tokens that matter.
The model didn't get dumber. The relevant context got buried under irrelevant context. And that's when I realized: the model wasn't the problem. The model was fine. What was missing was everything around the model — the process, the feedback, the memory, the isolation. I was blaming the engine for a chassis problem.
I identified five specific problems that cause an agent to meander from brilliant to foolish:
Context Rot
The Specification Gap
The Feedback Vacuum
Amnesia
Isolation Failure
Each one of these problems causes the agent to waste time and tokens on unnecessary work, retreading their steps, and generally being dumb.
But the five problems I'll describe here aren't specific to swarms. You'll hit every one of them with a single agent in a single session.
I've since built Oro, an agent swarm orchestrator that coordinates multiple agent workers to write, test, review, and merge code. But the five problems I'll describe here aren't specific to swarms. You'll hit every one of them with a single agent in a single session.
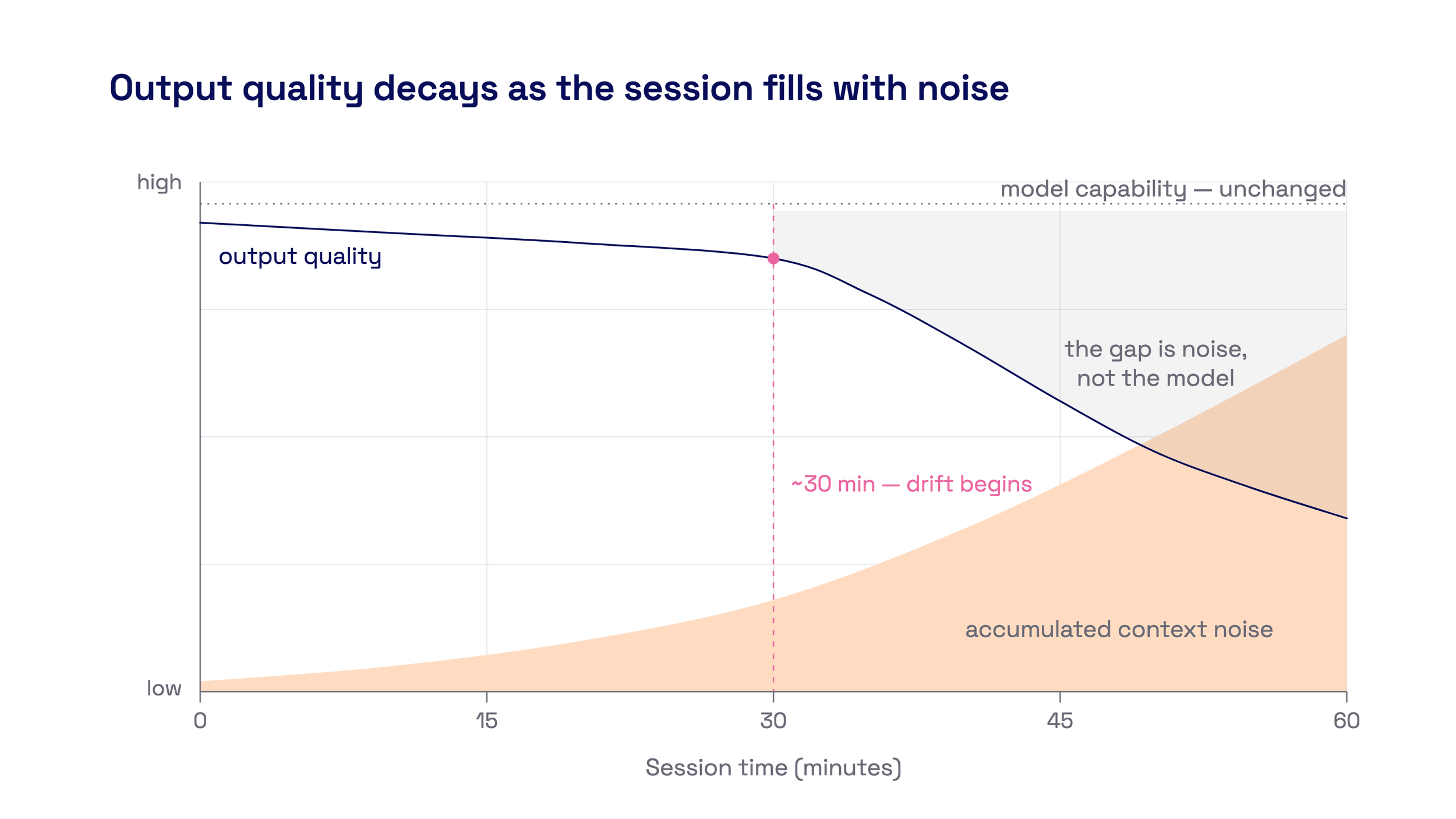
Agent output quality vs. session time. The signal-to-noise ratio degrades continuously.
1. Context Rot
Problem: The longer an agent works, the worse its output gets.
After 40 minutes, the context is packed with the full text of files read once, resolved discussions nobody will reference again, three abandoned approaches to a problem that's already solved. The model is still attending to all of it. The signal-to-noise ratio degrades continuously, and the output degrades with it.
Solution: Counterintuitively, give the agent less.
Each worker in Oro gets a single task — one atomic unit of work with clear acceptance criteria — in a clean git worktree. No history from prior tasks. No accumulated conversation. When a worker exhausts its context window, it executes a handoff and a fresh worker continues in the same worktree. The context resets. The work doesn't.
A worker that sees 200 lines of relevant code outperforms one drowning in 20,000 lines of everything. It works faster with less dead ends.
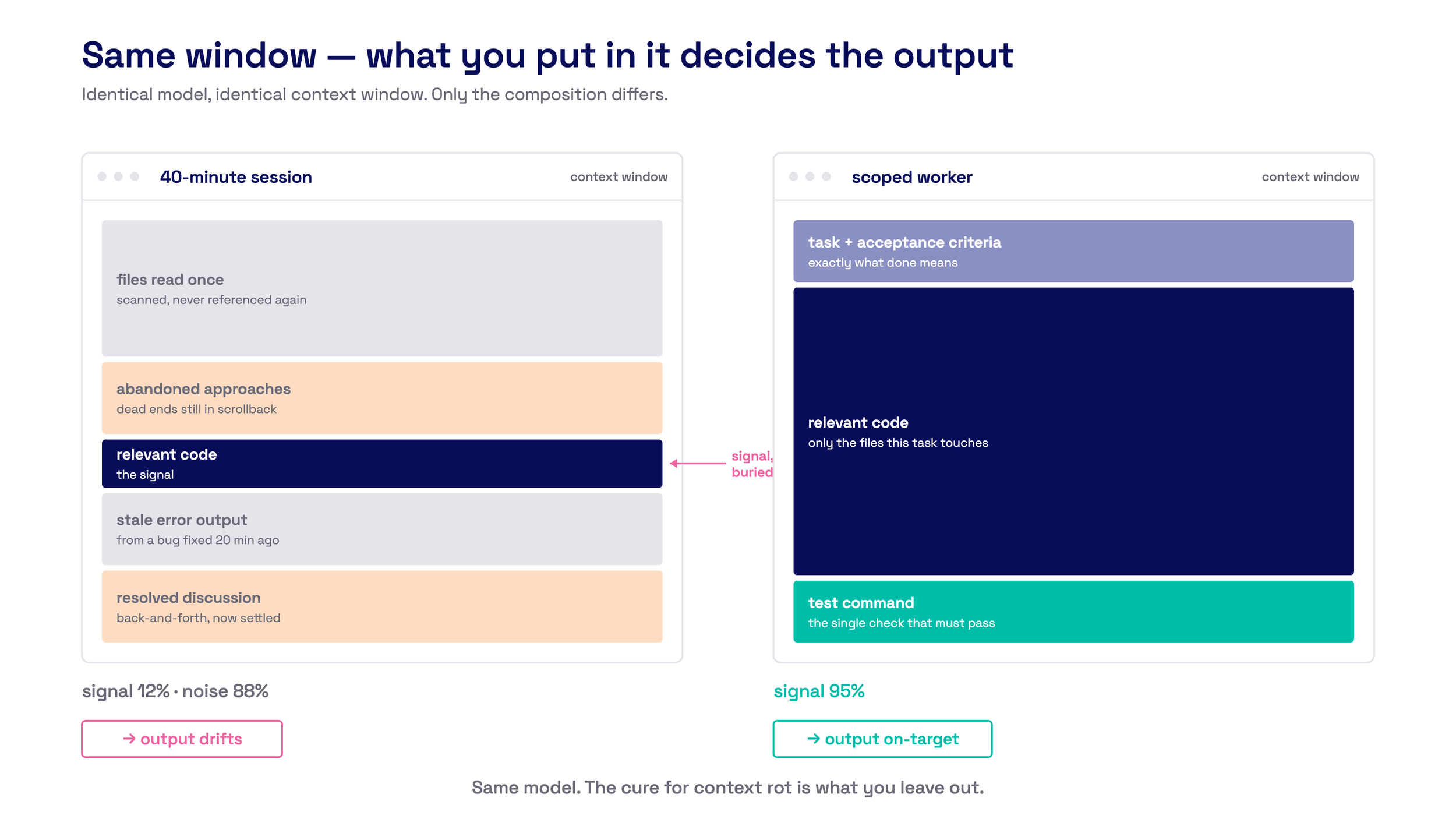
Same model, same window - only the composition differs. The fix for context rot is what you leave out.
2. The Specification Gap
Problem: Ask an agent to "add authentication" and you'll get something that compiles. You probably won't get what you meant.
Most slop originates here — not because the model can't code, but because it was given a vague target and hit it precisely. Vague spec in, vague code out. The model did exactly what you asked. The problem is what you asked.
Solution: Not more detailed prompts — a process that forces specificity before code exists.
Before any Oro worker writes a line of code, the spec runs through a gauntlet.
- Brainstorm 2-3 approaches with explicit trade-offs.
- Premortem every decision — what kills this in three months?
- Write a design doc. Then hand the doc to a separate agent, one that never saw the design conversation, whose only job is adversarial: Construct a scenario where every task passes individually but the feature still doesn't work.
- That reviewer traces actual call chains in the source code. It builds a matrix mapping every acceptance criterion to a specific task and test. It red-teams the decomposition. If it finds a gap — an unwired component, a missing integration test, a format mismatch between producer and consumer — the spec goes back for revision.
A token spent on specification saves ten tokens spent on rework. Every ambiguity resolved upstream is a hallucination that never happens downstream.
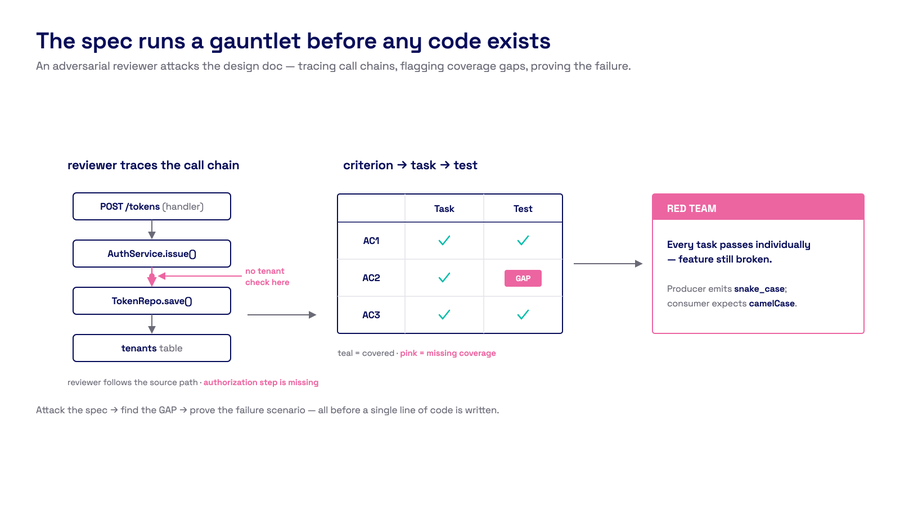
The adversarial reviewer attacks the spec before any code exists. Red lines trace call chains. GAP markers flag missing coverage.
3. The Feedback Vacuum
Problem: A human developer gets feedback constantly — the compiler, the test suite, the linter, the code reviewer, the tech lead who asks "why did you do it this way?"
An agent coding alone gets none of this. It writes code into silence.
The model can produce correct code. But without feedback loops, it has no way to distinguish correct from almost-correct. It can't know that the function it wrote matches the interface but handles errors differently than every other function in the codebase. It can't know that the test passes but doesn't actually test the thing that matters.
Solution: Make something push back — automated feedback the agent can't skip (also known as backpressure).
Oro wraps every unit of work in three independent gates.
- A 19-check quality gate — tests with race detection, linters, formatters, vulnerability scanners. Mechanical, deterministic, with no judgment required.
- a code review by a separate agent runtime instance that reads the diff against the acceptance criteria and the original spec, returning APPROVED or REJECTED with specific feedback.
- Human PR review
The worker cannot merge to prod without passing all three. Not "should pass" — cannot. Guards you can't skip are more valuable than best practices you should follow.
There's a secondary benefit here, too. Deterministic workflows let the agent keep instruction prompts focused on the problem at hand.
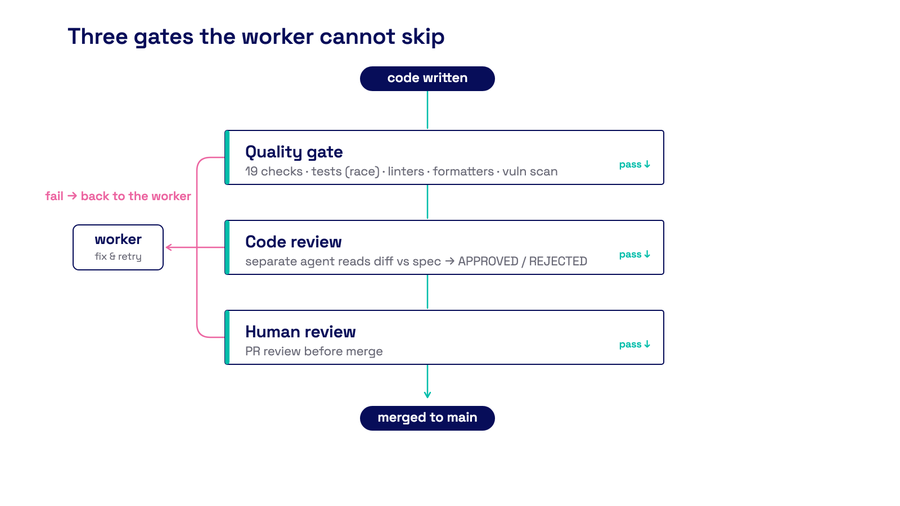
Three independent gates between code and production. The worker cannot skip any of them.
4. Amnesia
Problem: Every new coding session starts from zero. The agent doesn't remember that you prefer early returns, that the test database needs a specific seed, or that the last three attempts at this exact approach all failed for the same reason.
Humans build institutional knowledge over months. Agents lose theirs every time the context window resets.
Solution: Oro maintains a persistent memory store that workers read from and write to. Workers emit learnings during execution — patterns, decisions, gotchas. Before assigning a task, the dispatcher queries the top relevant memories and injects them into the worker's prompt, annotated with age so workers verify stale claims against current code.
Oro agents even dream. Every ten completed tasks, a consolidation agent reads the entire memory table and synthesizes across sessions — merging duplicates, deleting contradictions, surfacing patterns that no individual worker could see. A gotcha encountered in week one prevents the same mistake in week eight, without a human curating anything. The swarm accumulates judgment the way a team does, except it never forgets and it never leaves.
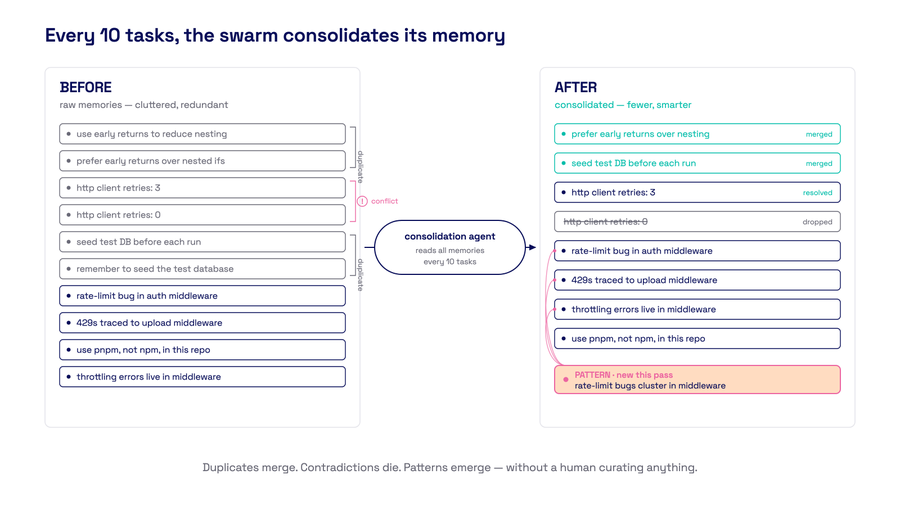
Every 10 tasks, a consolidation agent synthesizes across sessions. Duplicates merge. Contradictions die. Patterns emerge.
5. Isolation Failure
Problem: The moment you want two agents working concurrently, everything breaks. They edit the same files. They make conflicting architectural decisions. They produce interfaces that compile independently but don't agree with each other.
Two agents produce occasional conflicts. Four agents produce constant ones. The naive solution — run them sequentially — throws away the only reason you have multiple agents.
Solution: Each Oro worker operates in its own git worktree on its own branch. They cannot see each other's uncommitted changes. When a worker finishes, a coordinator serializes the merge: rebase, verify the quality gate passes on the rebased code, then fast-forward into the main branch. If a rebase conflicts, a separate agent resolves it. Linear history, every commit tested, no silent collisions.
Isolation makes concurrency possible. Without it, you're just running multiple agents in the same room with the lights off.
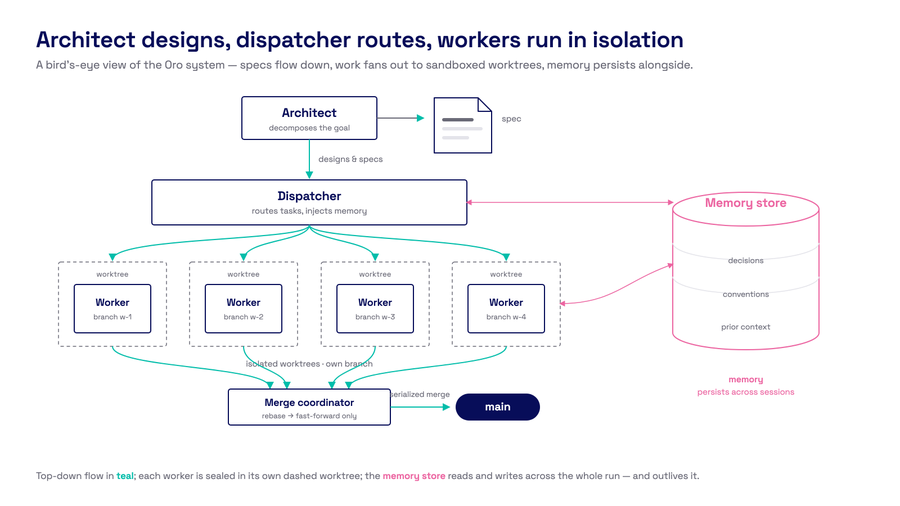
The full system. Architect designs, dispatcher coordinates, workers execute in isolation, memory persists across sessions.
The Harness Is Universal
These five problems — context rot, specification gaps, feedback vacuums, amnesia, isolation failure — aren't exotic. They're what happens every time you hand an LLM a coding task without structure around it. You can solve them with Oro, or with your own tooling, or with discipline and a checklist. But you can't ignore them and expect clean output.
Scope the context. Specify before you generate. Add mechanical feedback that can't be skipped. Persist what you learn. Isolate concurrent work.
A better model in a bad harness still produces slop. A good model in a good harness compounds. The model was never the bottleneck.
Oro is an open-source autonomous agent swarm orchestrator. It coordinates agent workers to execute software engineering tasks with TDD, quality gates, code review, and cross-session memory baked into every cycle.

GitHub and Claude Are Down Three Out of Four Days
146 out of 198 days, at least Github or Claude had an incident. GitHub averages 91% uptime, Claude 80%. Six months of status page data visualized.
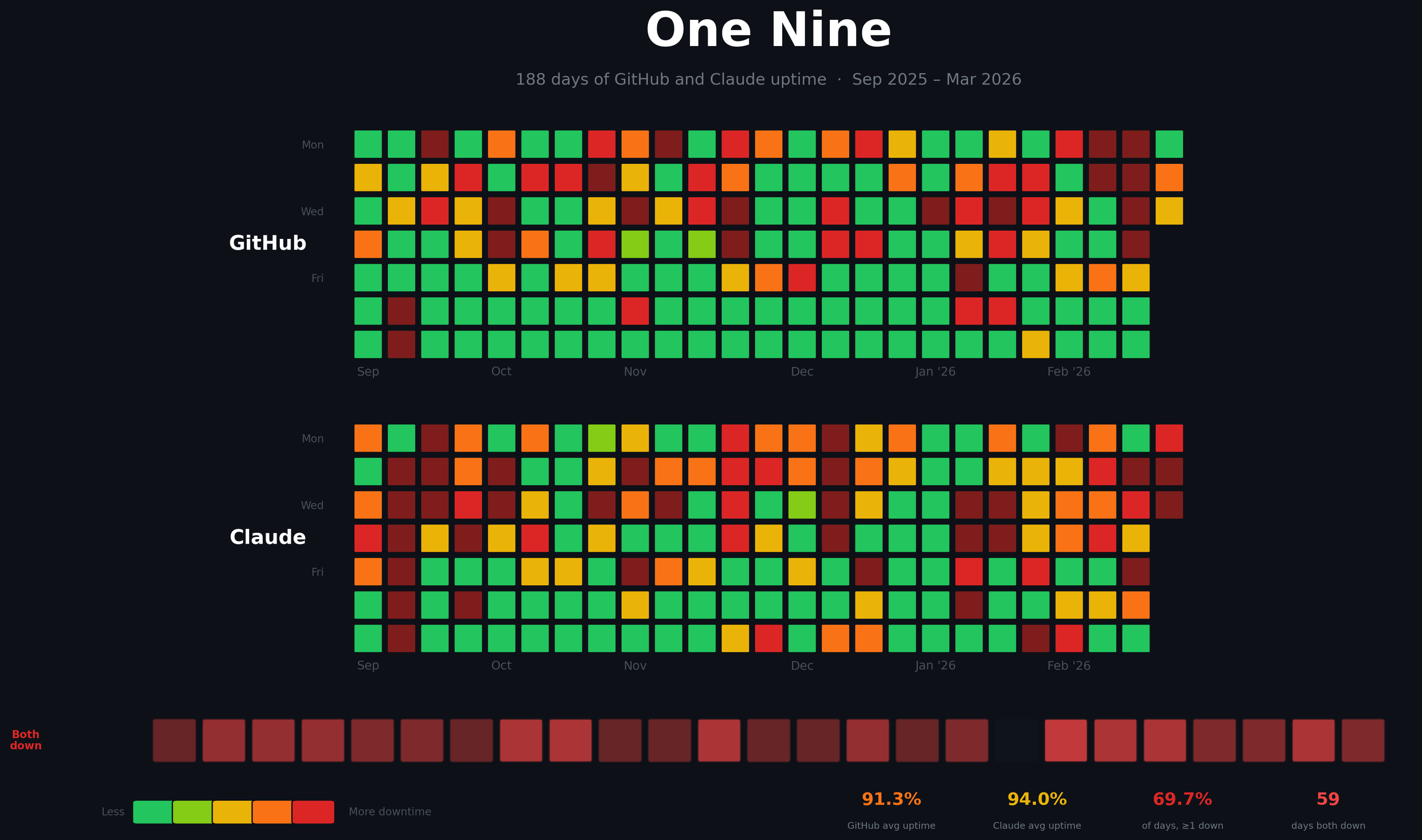
GitHub's average uptime since September: 91%. Claude's: 80.4%.
146 out of 198 days, at least one of them had an incident.
We've gone fully agentic at Wyndly, my telehealth allergy practice committed to curing everyone's allergies forever. Doctors, care teams, engineers all running agents daily. When these services go down, care decisions slow down.
Maybe your git push went through. Probably.
Six months ago, I'd have migrated immediately. Then I looked at what happened on Christmas, 2025.
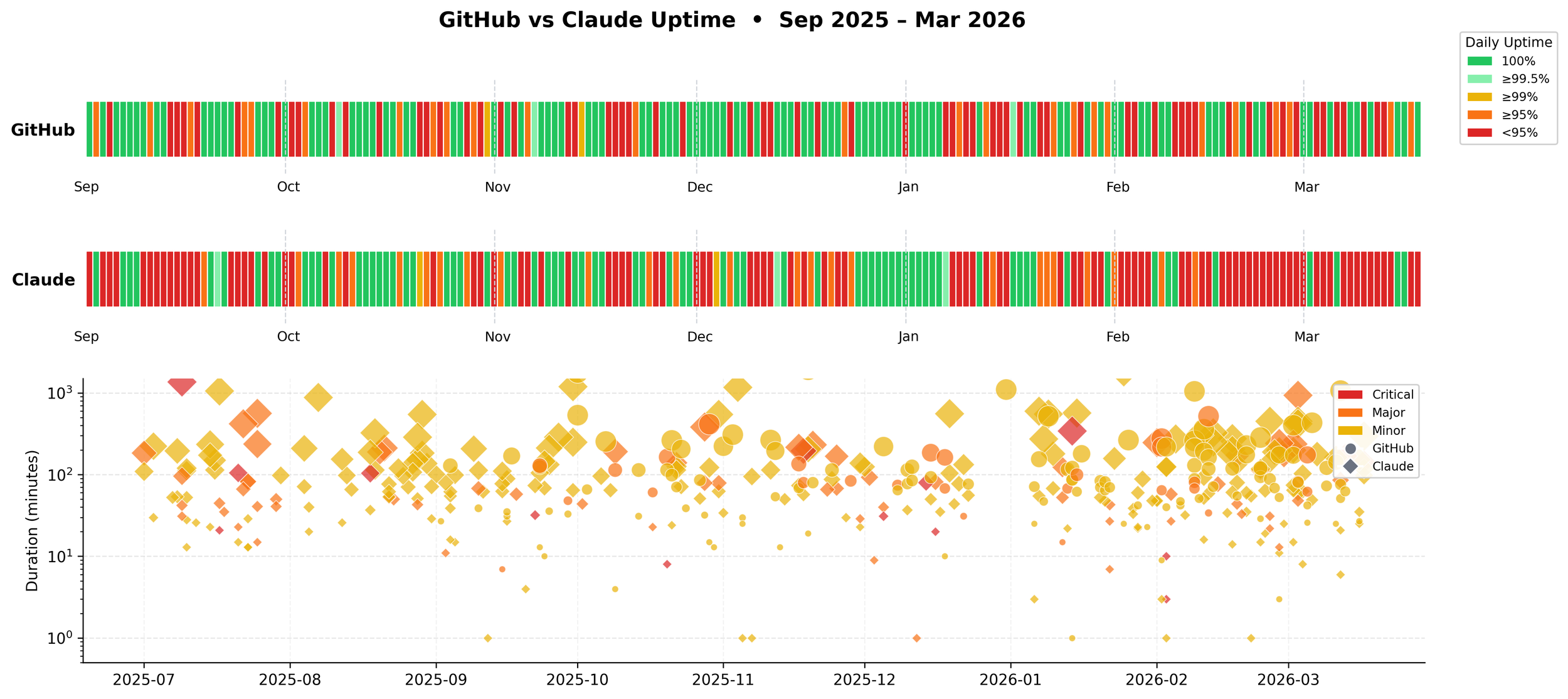
198 days. 146 with at least one incident.
The Heatmap of Hell
The heatmap above should be all green. Instead, it's red, very, very often. Green days are perfect. Red days are bad.
- 146 out of 198 days (73.7%), at least one of these two services had an incident. Three out of every four days.
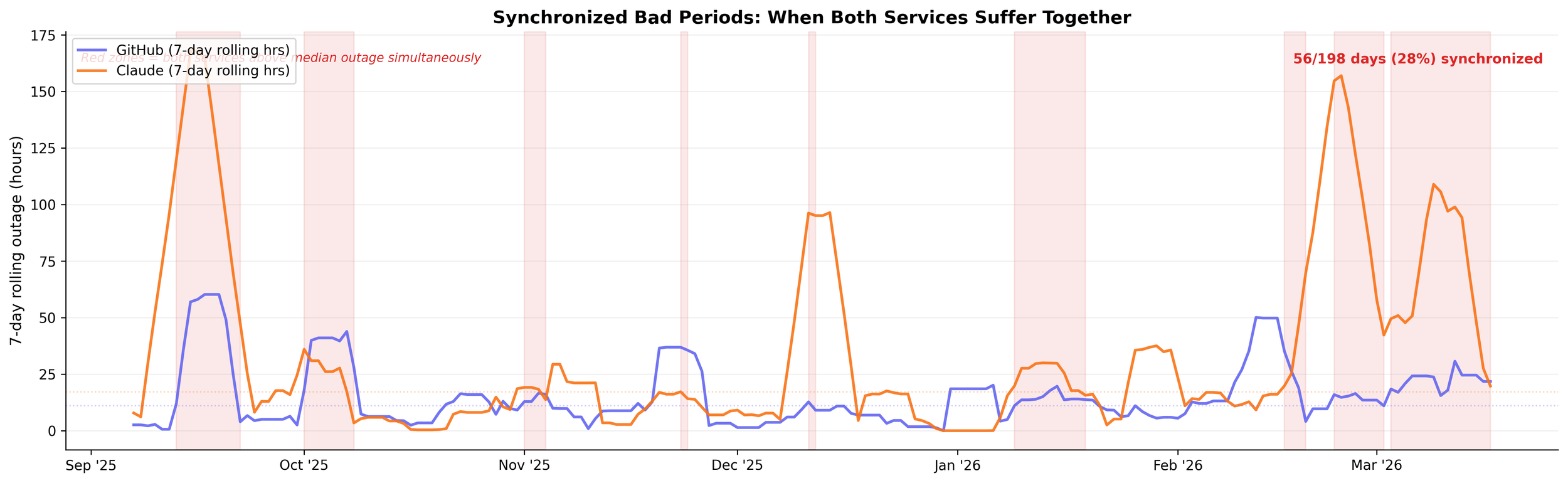
- 74 days both GitHub and Claude were down simultaneously.
- March 2026 is the worst month on record for Claude at 62.4% average uptime. GitHub is at 87.9%. Both services have been getting worse since December.
GitHub has accumulated 418 hours of total outage time since September, over seventeen full days. Claude has accumulated 934 hours, nearly thirty-nine days.
Is downtime related?
I ran the correlation between GitHub and Claude daily outage minutes: r = 0.197. A weak correlation. Not great, not terrible.
That was the wrong question.
The severity of outages is uncorrelated: a bad day for GitHub says nothing about how bad Claude's day will be. But when they fail is strikingly similar. Like Khalid and Dove Cameron, they go down together.
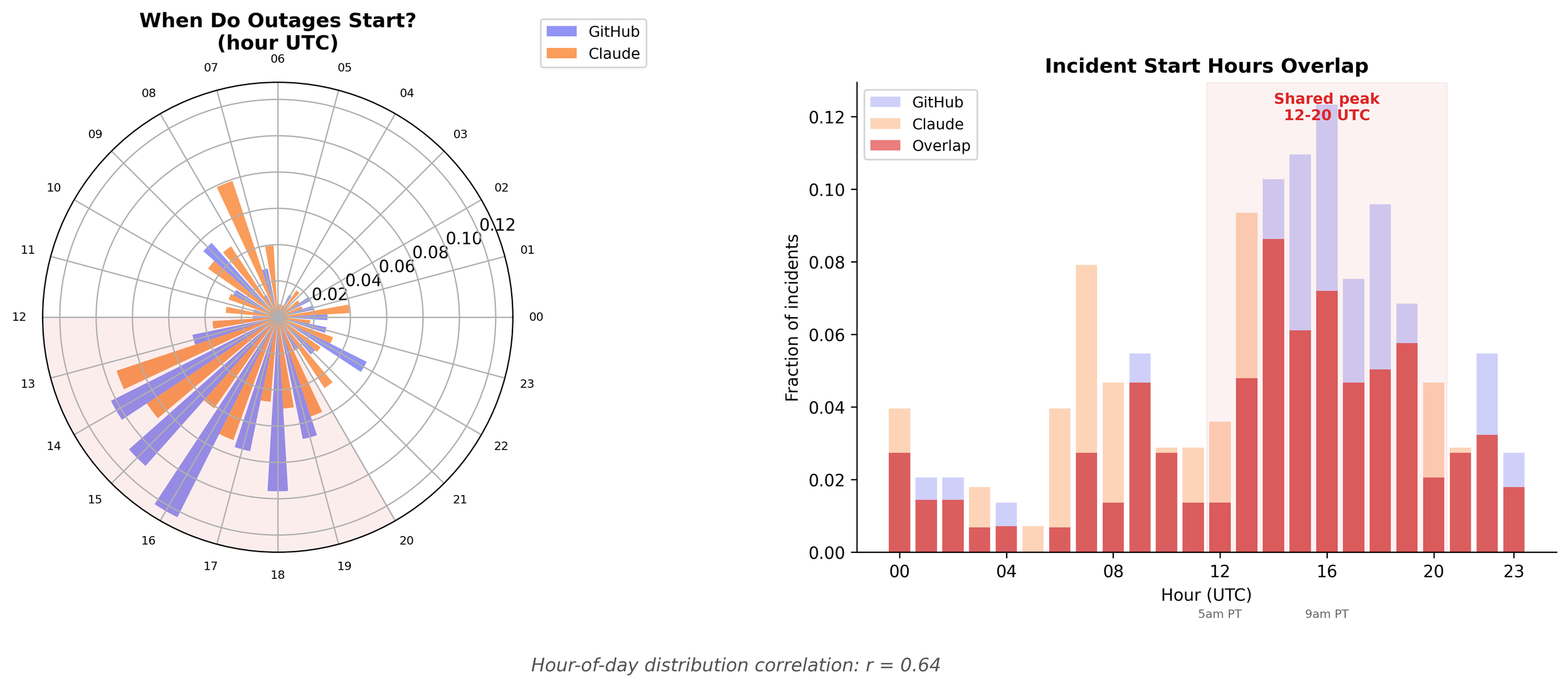
Outages occur together
Both services cluster incidents between 12:00 and 20:00 UTC. Hour-of-day correlation: r = 0.64.
Deployments happen during the workday. Traffic spikes during the workday. The humans who push the code that causes the incidents are mostly in US time zones. So all that load concentrates, and then, boom, outages. Unfortunately, outages when you're trying to work and use these services.
Contagion
When GitHub has an incident on day T, the probability that Claude has an incident on day T+1 rises from a 63.1% baseline to 75.8%. The reverse holds: Claude down on day T lifts GitHub's next-day probability from 48.0% to 58.1%.
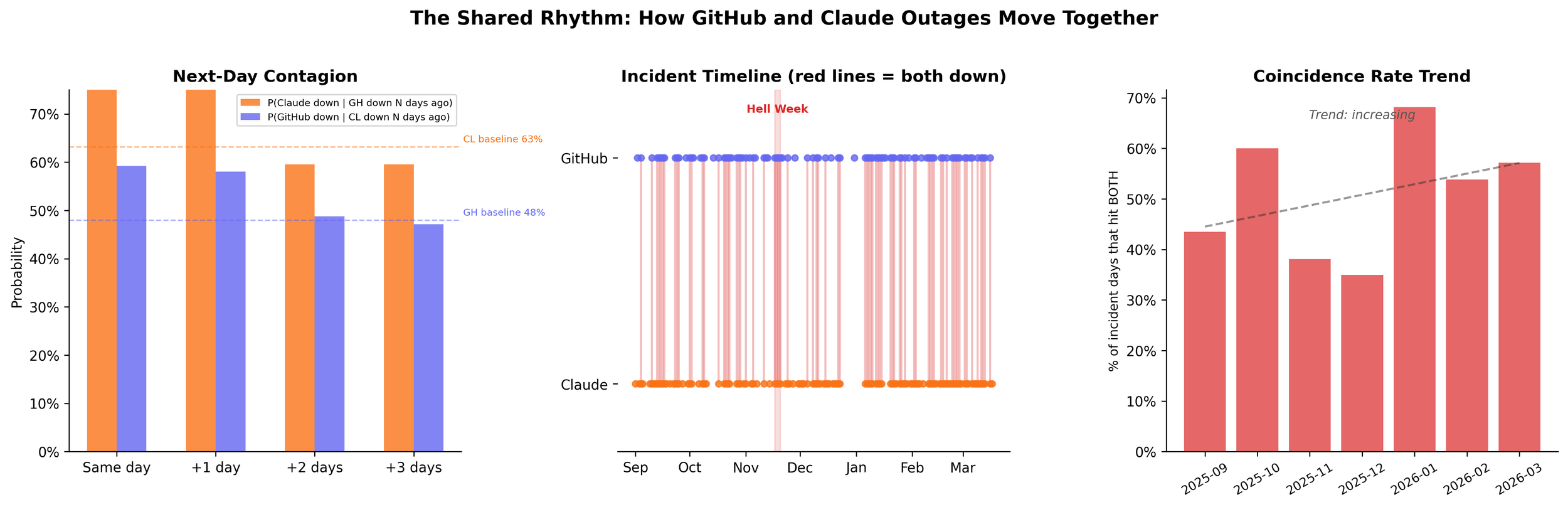
I don't think one service is causing the other to go down. But it's not out of the question.
The coincidence rate has more than doubled. In September 2025, about 23% of days saw both services with incidents. By February-March 2026, that number is above 47%.
Christmas every weekend
From December 24 through January 1, Claude had zero incidents. Not degraded. Not minor. Zero. GitHub had one. Then January 2 hit, and both services returned to their normal cadence immediately.
That holiday window isn't special. It happens every week(end).
GitHub is up 89.3% on weekdays and 96.5% on weekends. Incidents touch 62% of weekdays and 11% of weekends. Claude shows the same pattern: 92.5% weekday, 97.8% weekend. Tuesday through Thursday is the danger zone. Sunday is practically a different service.
These systems don't fail randomly. They fail when engineers are working. A broken system breaks on Christmas too — these ones work fine on Christmas, on Saturdays, at 3 AM. They buckle on Tuesday afternoon.
What this means
The coincidence rate — days both were down — climbed from 23% in September to 47% in March. It's not random. It's because they're winning.
GitHub and Claude are the default stack for agentic development. Every team that adopts AI-assisted coding adds load to both services in the same business-hours window.
The adoption wave won't wait for the infrastructure to catch up. Nobody's going back to writing code by hand because Claude was down on a Tuesday.
Methodology
What counts as downtime
These numbers are based on self-reported status page data. An incident counts as downtime if the service operator marked it with impact minor, major, or critical. Incidents marked none and scheduled maintenance windows are excluded.
Daily uptime is the fraction of minutes in the day not covered by an active incident: 1 - (outage_minutes / 1440). Overlapping windows are merged before summing. A day with a one-hour incident scores 95.8%. Multi-day incidents count against every calendar day they span.
This means the numbers are a floor, not a ceiling. Status pages are conservative — they get updated after engineers confirm a problem, and they get closed before every affected user recovers. The real degradation window is almost always longer than what's recorded here.
Data sources: mrshu/github-statuses for GitHub downtime windows, https://status.claude.com/history for Claude incidents. Analysis covers September 1, 2025 through March 17, 2026 (198 days).
Aakash Shah is the co-founder of Wyndly, bringing allergy care to all Americans, with humans superpowered by AI. When the infrastructure goes down, care decisions slow down too. It's why his team thinks about these failure patterns constantly. He also has his own Yegge Level 8 Agent Harness.
All My Advice for Getting into YC
I participated in YC W21 with Wyndly (https://www.wyndly.com). I've also coached 8 people into YC. Many of these coached have gone on to raise unimaginable amounts and build sustaining companies.
Introduction
Successful YC applications follow a three-part framework:
- Identify your fundraising vertebrae - The 2-3 specific reasons investors would fund you
- Craft independent, powerful answers - Each question should stand alone as evidence of your potential
- Weave an overarching narrative - Connect everything into a compelling story about your inevitable success
Let's walk through how to execute each step effectively.
Step 1: Identify Your Fundraising Vertebrae
Begin by honestly assessing which 2-3 of these strengths form the backbone of your investment case:
- Traction: Impressive user/revenue growth (e.g., "20% week-over-week growth for 6 months")
- Market Size: Clear path to massive TAM (e.g., "$50B addressable market growing 15% annually")
- Unique Insight: Novel approach others have missed (e.g., "We discovered enterprise customers value X over Y")
- Team Advantage: Exceptional domain expertise or prior success (e.g., "We built and sold a similar product")
- Product Innovation: Technical or UX breakthrough (e.g., "Our algorithm improves accuracy by 40%")
- Problem Urgency: Critical pain point with growing demand (e.g., "Companies lose $5M annually to this issue")
Action steps:
- List evidence for each category
- Identify your 2-3 strongest vertebrae with concrete metrics
- Ensure these strengths appear consistently throughout your application
Step 2: Structure Each Answer Independently
For each application question:
The Formula
- Lead with your main point in the first sentence
- Include just 1-2 key messages that demonstrate business mastery
- Provide concrete evidence (metrics, experiments, customer quotes)
- Connect back to your vertebrae
Key Questions to Prepare
- What are you building? (Product focus)
- Who are you? (Team strength)
- How far along are you? (Traction evidence)
- What's the market opportunity? (Size and growth)
- Why will this become a $10B company? (Growth trajectory)
Action steps:
- Draft each answer separately
- Review to ensure each could stand alone
- Cut any content that doesn't directly support your vertebrae
Step 3: Craft Your Overarching Narrative
Thread these elements into a compelling story:
The Five-Part Structure
- Hook: The insight or opportunity that makes your venture unmissable
- Characters: What makes your founding team uniquely positioned to win
- Struggle: The critical problem you're addressing (and why it matters)
- Triumph: Early wins that validate your approach
- Determination: Why you'll succeed regardless of obstacles
Action steps:
- Identify your most compelling hook
- Highlight founder qualities that specifically match your problem
- Ensure your early wins directly validate your approach
- Demonstrate commitment beyond typical founder enthusiasm
Final Review Checklist
Before submitting, verify your application:
- Opens every answer with the main point immediately
- Consistently highlights your 2-3 vertebrae throughout
- Provides specific metrics rather than general claims
- Demonstrates deep domain expertise & business mastery
- Uses authentic, bullshit-free language
- Keeps all answers concise
- Makes a clear case for $10B potential
- Tells a cohesive story across all questions
Remember: YC partners review thousands of applications. Your job is to quickly demonstrate you're building something that could fundamentally reshape an industry and create billions in value.
Resources
How to Apply and Succeed at Y Combinator by Dalton Caldwell, YC Partner
Fundraising Vertebrae by me
How to Answer Questions on the Y Combinator Application by me
Essential Advice to Land a YC Interview
I've gone through YC (W21). I've also coached 5 people and gotten them into YC.
Here's the advice I always give everyone:
The main takeaway of each answer should be said as quickly as possible right at the top. There should be 1-3 central things that we want to communicate – nothing more.
The following should be the goal for each answer:
DEMONSTRATE THIS IS A $10B company!
Informative
No bullshit
Authentic
Math-backed
Review these resource:
How to Apply and Succeed at Y Combinator by Dalton Caldwell, YC Partner
Fundraising Vertebrae by me
How to Answer Questions on the Y Combinator Application by me